Variographic analysis
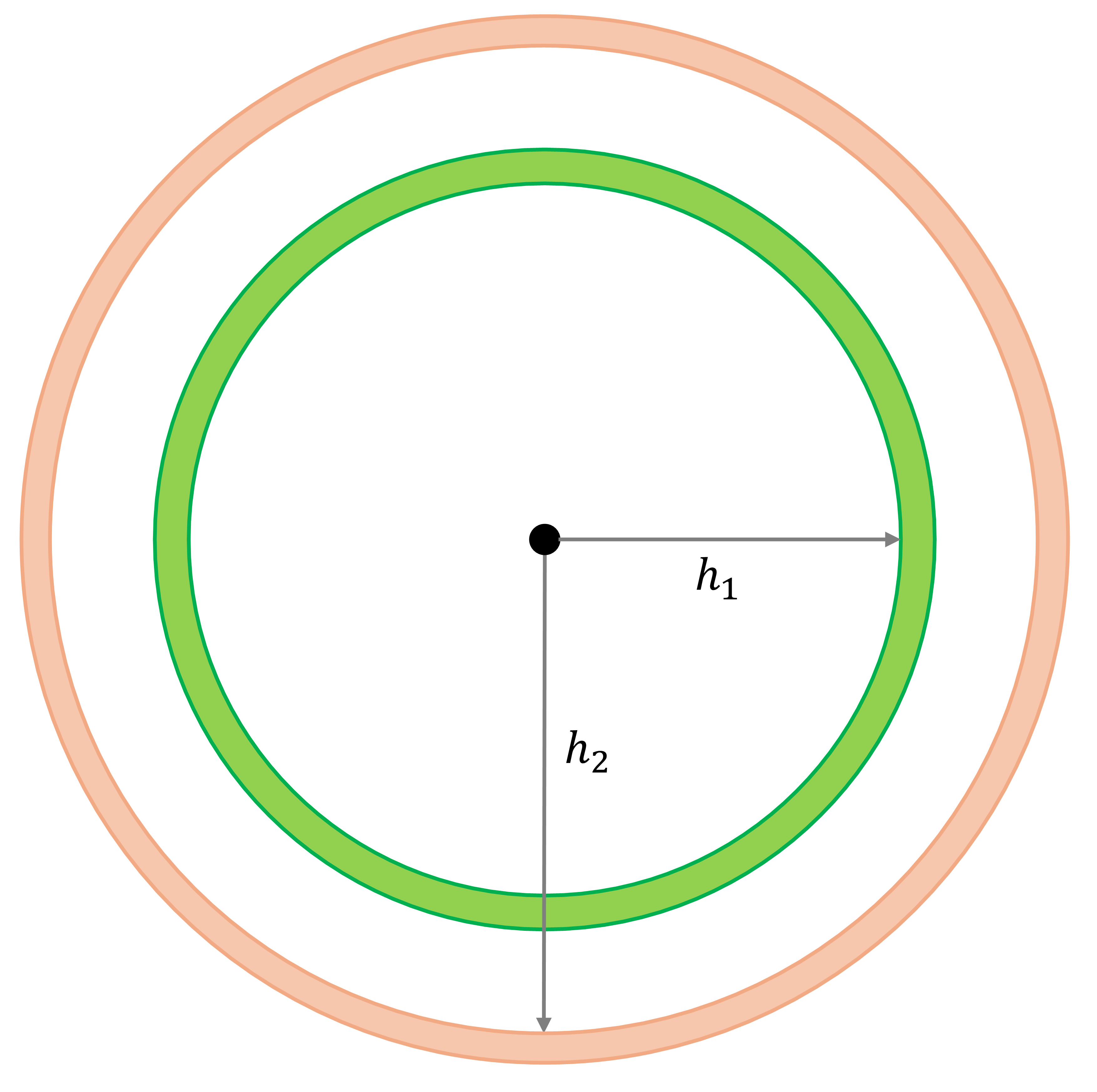
We define a binary spatial weight matrix as:
\[ w_{ij}(h)=\bigg\{\begin{array}{l l} 1\text{, if } d_{ij} = h\\ 0\text{, otherwise}\\ \end{array} \]
Covariogram and semivariogram
Covariogram:

Semivariogram:
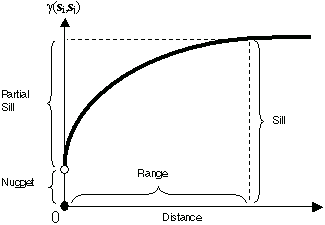
The autocovariance, \(C_{z}(h)\), and semivariance, \(\hat{\gamma}_{z}(h)\), are related as follows: \[ C_{z}(h) = \sigma^2 - \hat{\gamma}_{z}(h) \] where \(\sigma^2\) is the sample variance.